Architecture
IaaS Platforms
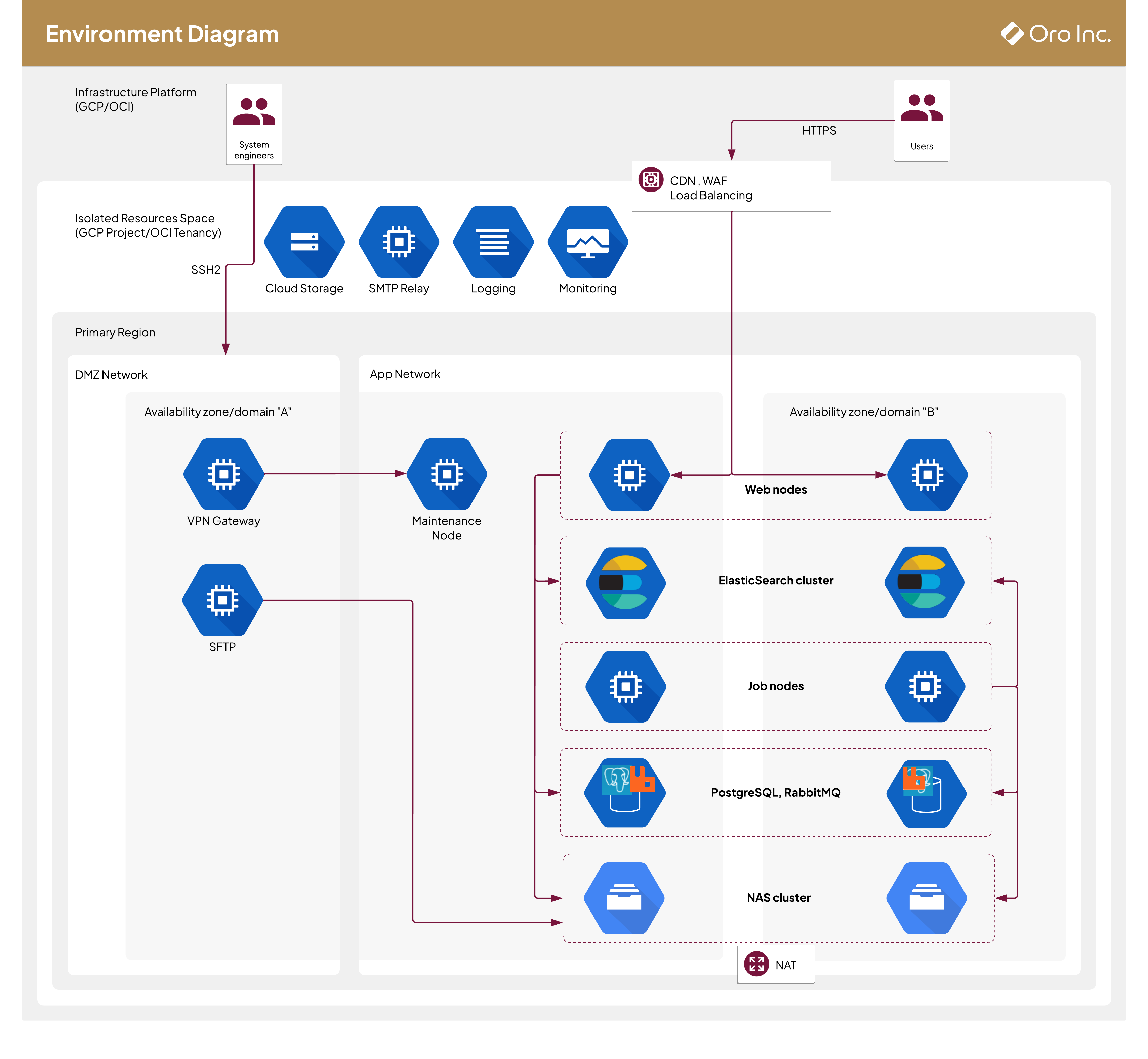
OroCloud supports two IaaS platforms – Google Cloud Platform and Oracle Cloud Infrastructure (OCI) out-of-the-box. Both these platforms have similar approaches to support high availability and disaster recovery using many data centers located all around the globe. To organize IaaS resources for a particular OroCloud environment, the resources are grouped into a GCP project or OCI tenancy. Within a single project or tenancy, resources are optimized for data transmission and communication within the same region and provide redundancy for high availability with redundant resources distributed among multiple zones.
IaaS Data Centers
Google’s and Oracle’s data centers are located in the US, South America, Europe, and Asia. Fore more information, see GCP Data center locations and OCI Data centers.
IaaS providers organize their resources into zones or availability domains to ensure:
Fault tolerance, as every zone/domain is isolated from other zones. It is highly unlikely for two zones/domains to fail from the same cause.
Fast network connectivity between zones/domains in the same region, resulting in latency of under 5ms.
On-demand resource distribution to multiple regions and protection from global disasters that may affect an entire region.
In OroCloud, you can choose the IaaS region(s) for your Oro application environment. To ensure fault tolerance, all resources generally reside in the same geographic region for optimized response time, but they are distributed across multiple zones within that selected region.
OroCloud Environment Infrastructure Diagram
The diagram below reflects a standard Oro application deployment in IaaS platform via OroCloud.
Redundancy
Redundancy is a system design that ensures all system components are duplicated. In the event one of the hosts fails, the system can run using the redundant host.
The OroCloud infrastructure uses fully redundant components and services for Oro application operations. Check out the following sections for details on how redundancy is achieved.
CDN and Load Balancing
The content delivery network is the geographically distributed network of the caching proxy servers that help improve response time for static content and provide high availability for service.
Load Balancing is the process of distributing incoming traffic among web servers to improve service availability and performance. OroCloud offers two options of CDN and load balancing depending on the service provider used.
GCP
Google CDN uses edge servers distributed globally and perfectly integrated with Google Cloud Platform logging and monitoring services. For more information, see CDN and Load Balancing documentation.
Load Balancing uses a standard GCP load balancer, which distributes traffic between web nodes. This option provides a basic level of DDoS mitigation and leaves service entry points exposed to the world due to the GCP architecture requirements.
Please note that GCP CDN and load balancing is available only for GCP hosting.
Cloudflare
Cloudflare is a leading content delivery network (CDN) and web application security service. It helps improve response time for static content, protects from DDoS attacks, and provides high availability for the web application. Cloudflare uses a connectivity cloud distributed globally to connect end-users to an OroCommerce instance, improving performance and providing an additional layer of network security. Please refer to the Cloudflare documentation for more details.
An OroCommerce instance protected by Cloudflare Zero Trust has no entry points exposed to the public Internet. Instead, it connects securely to the Cloudflare Connectivity Cloud through a lightweight daemon (cloudflared), which runs in a web node. This daemon establishes an encrypted tunnel to Cloudflare using the QUIC protocol. End-user requests to the specific OroCommerce site are received by Cloudflare, which then routes the traffic through the secure tunnel to the specific OroCommerce instance. This process is seamless for the end-user and addresses the most common security and availability risks, including DDoS attacks.
Key details for an OroCommerce instance protected by Cloudflare:
The TLS (SSL) certificate for the site is managed by Oro through Cloudflare Connectivity Cloud.
HTTPS connections are terminated in the Cloudflare Connectivity Cloud, after which all traffic is routed within Cloudflare’s infrastructure and then through the secure, encrypted tunnel to the specific OroCommerce instance.
Load balancing is performed using nginx load balancing capabilities.
Cloudflare is available both for GCP and OCI-hosted environments.
Oro customers can also choose to utilize alternative CDN providers. Please contact Oro Support to check if your CDN is compatible with the Oro application.
Web Node
Inbound traffic is balanced between the web nodes. This enables on-demand scaling, fault tolerance, DDoS protection, etc. At least two web nodes are allocated in different availability zones/domains for fault-tolerance.
Search Index
To speed up the search, Oro application data is indexed according to the application configurations and stored in the search index. As a search index provider, OroCloud instances use ElasticSearch which provides cluster architecture out-of-the-box as well as the ability to add more nodes to clusters to spread the load and enhance reliability. For more information, see the Life Inside the Cluster documentation.
Database
Oro application data is stored in the PostgreSQL relational database. Each environment has at least two PostgreSQL instances, one in the main zone and another in the secondary zone. If the instance in the main zone becomes unresponsive, the environment automatically switches to the secondary zone enabling the database failover.
Job / Message Queue
Oro application uses RabbitMQ as a message queue broker to enable asynchronous processing for heavy jobs. RabbitMQ is highly scalable and supports cluster architecture out-of-the-box. RabbitMQ brokers tolerate the failure of individual nodes. Nodes can be initiated and stopped at will, as long as they can contact a cluster member node known at the time of shutdown. See RabbitMQ Clustering for more information.
To process queued messages, Oro application uses a proprietary consumer service. It runs as a daemon and handles all the jobs (messages) registered within a message queue.
The consumer service is scalable and can run as parallel processes on multiple hosts to handle a large volume of messages. To guarantee an acceptable response time and address spikes to the server-side workload, message processing can be scaled by adding more consumer services.
SMTP Relay
To send emails from an OroCloud environment, the Oro application uses the dedicated SMTP Relay service, which provides high availability using a set of mail relays with different priorities. The setup is similar to a master-master database replication, where there is more than one active service to handle the requests.
See Set Up SMTP for Applications on OroCloud for more information.
Cache
Oro application uses Redis cluster to store cache which optimizes processing of complex operations. Redis Sentinel provides high availability for Redis cluster via the automatic failover and failure detection.
See Redis Sentinel Documentation for more information.
File Storage
OroCloud environments are configured with a GridFS clustered file system to store application files related to the user data (attachments, images, documents).
Backups and Restore
Backups of OroCloud environment include the database dump, media files, and either the application source code or the repository commit hash that may be used to retrieve the code.
Schedule and Backup Retention Policy
Oro maintains a regular backup process which covers both database and media content. There are 3 types of backups depending on the target recovery point objective (RPO):
Hourly backups. RPO - 1 hour. Oro stores hourly backups for the last 7 days.
Weekly backups. RPO - Sunday Oro stores weekly backups for the last 4 weeks.
Monthly backups. RPO - last Sunday of the month. Oro stores monthly backups for the last 12 month.
You can get the list of available backups and restore to the specific recovery point using maintenance tool commands.
Encryption
The backed up data is encrypted using AES-256 keys.
RTO
Restore time objective may vary from 30 minutes up to a couple of hours depending on the amount of data to be restored.
Maintenance
To maintain optimal performance, reliability, and security, the OroCloud team performs regular environment maintenance where the team may roll out environment updates during the predefined maintenance window. During the events when a critical infrastructure security patch is released or some maintenance activity is urgently required for security or performance reasons, the OroCloud Services team reserves the right for unplanned maintenance windows. The Oro team will inform the environment owner about such maintenance activity.
Disaster Recovery
Disaster Recovery (DR) is a process that allows the IT support team to recover OroCloud service operations during a total failure or major malfunction of main hosting resources.
While every tier of IaaS resources is redundant, there is still a chance a catastrophe can shut down the entire IaaS region. For service disruption, IaaS Region failure should suffice but may not be required. Internet connectivity issues outside of the provider and Oro’s control may be caused by adversary actions or misconfiguration and may as well take down the Oro Cloud environments in a particular region.
Disaster Recovery Objectives and Criteria
The following criteria define an event is classified under Disaster Recovery on OroCloud:
The IaaS Region hosting a particular OroCloud environment is not available and is not anticipated to be recovered by the provider in the next hour.
The OroCloud environment is not accessible because of network issues related to the IaaS region geographical location.
In the event of a disaster, the OroCloud team takes the following disaster recovery objectives:
Recovery Point Objective - The instance is restored from the last daily backup.
Minimal Recovery Time - It takes at least 60 minutes to restore service availability after the disaster recovery has been approved.
Maximum Recovery Time - The recovery time depends on the backup volume and the complexity of the integration.
Disaster Recovery Principles
Oro uses a cold disaster recovery location. No resources are allocated or billed until the disaster recovery is initiated. In case a disastrous event takes place at the primary location, the OroCloud environment is re-created at a different IaaS Region unaffected by the disaster. Each IaaS Region that is used for production hosting has a designated Disaster Recovery location.
Oro provides both primary and Disaster Recovery IP addresses to the customer as part of onboarding information. These IP addresses must be added to the whitelists if any whitelisting is used.
Disaster Recovery Flow
Customer Support will request DR approval by contacting environment owner technical contact person.
Once the DR is approved, the OroCloud SWAT team uses the following action plan:
Provision the DR infrastructure and restore the latest backups at the new infrastructure
Update the DNS record to point to the new location (if possible)
Perform health checks for the restored instance
Once the health check for the restored instance is complete and the instance is up and running, Customer Support will notify the technical contact that the service has been successfully restored.
Note
If the Oro application is configured with the customer-managed domain, the DNS record update should be handled by the domain owner.
System Configuration
System configuration is managed as a code via the configuration management tool (Puppet).
What’s Next
OroCloud security
The typical process of OroCloud onboarding, including the secure certificate exchange and guided access to the necessary tools
The guidance on using OroCloud Maintenance Tools for deployment and maintenance
Monitoring principles and tools
Information on how OroCloud team handles incidents
Technical support service details (exclusions, priorities, SLA, etc).
Business Tip
Looking for a new B2B marketplace solution? Become familiar with online B2B marketplaces and how they create value for your business.